Cognitive science
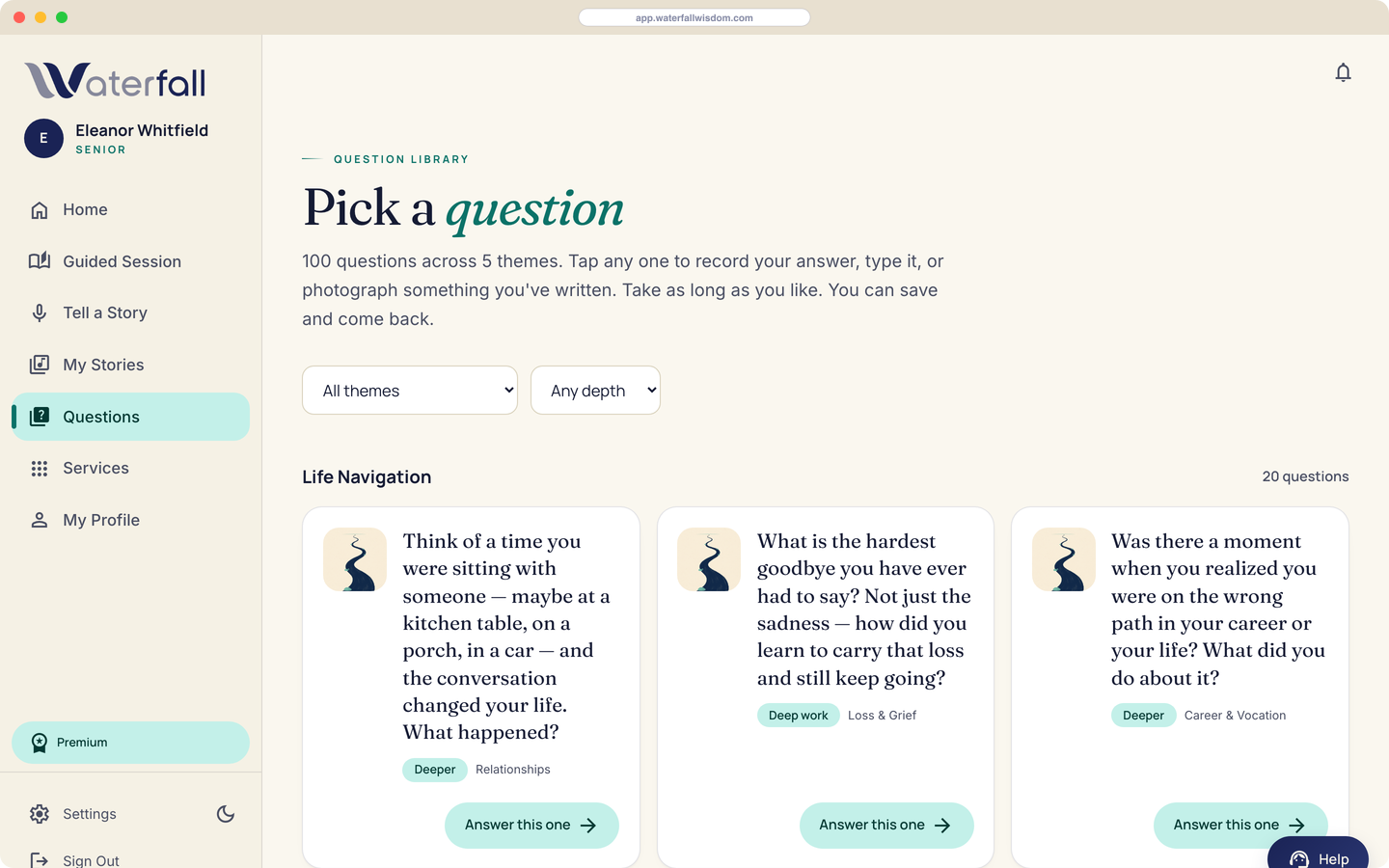
Episodic memory and encoding specificity. The questions are designed to surface specific scenes, not generalised accounts — because that is where the lesson actually lives.
- Tulving, 1972
- Tulving & Thomson, 1973
- Conway & Pleydell-Pearce, 2000